DeepSeek V4’s technical report includes mHC, CSA, HCA, Muon, and FP4, but notably lacks Engram.
Where has Engram gone?
This topic has become a hot discussion among netizens. Engram was jointly open-sourced by DeepSeek and Peking University in January, focusing on memory and efficiency issues in large models. Since its appearance on arXiv, discussions around it have not ceased.
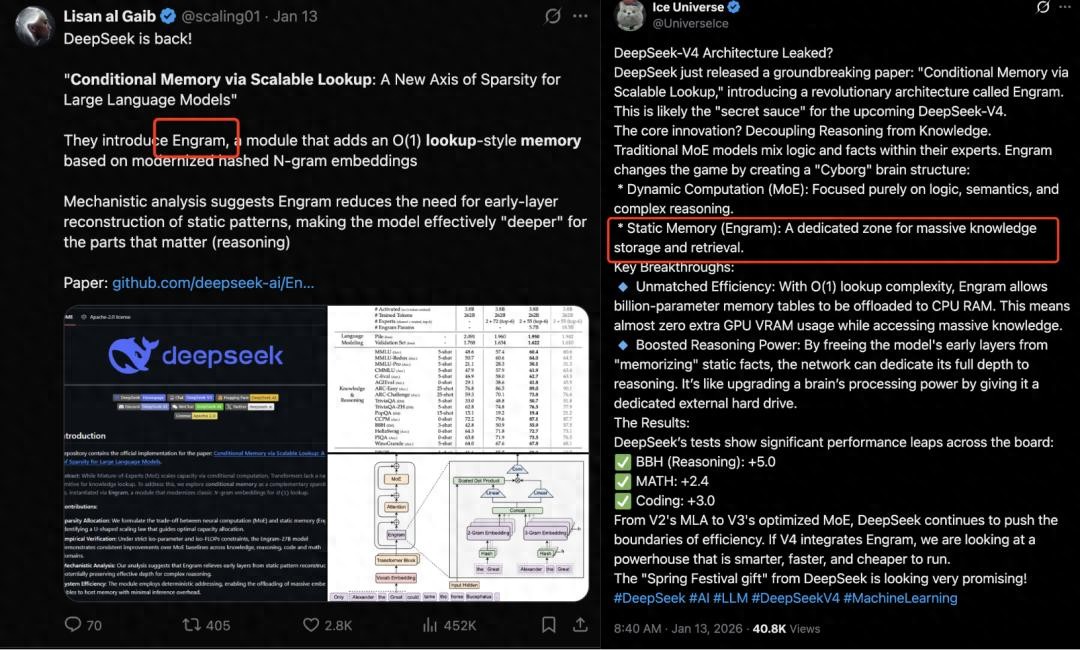
Not only is it a precursor to V4, but with Engram, facts like “London is the capital of the UK” can be retrieved without re-running the entire deep network, saving memory and freeing up network capacity for higher-order reasoning.
Since the paper’s publication in early January, many believed that Engram was the foundational architecture for V4, and everyone was eagerly anticipating its inclusion.
Thus, when V4 was released, many immediately searched the paper for Engram, but unfortunately, it was absent.
Many users even felt that without Engram, V4 was incomplete.
The absence of Engram might be the biggest regret of DeepSeek V4.
However, Engram has not disappeared. Three noteworthy papers have since emerged:
- CXL Memory Pooling Version: Integrating Engram into a shared CXL memory pool across multiple machines to address storage issues in large model deployments.
- Collision-Free Hot Tier Experiment: Empirical testing of multi-head hash optimizations for Engram, disproving some intuitive improvement schemes.
- Visual Tiny Engram: The AutoArk team has adapted text-based Engram for visual modalities, expanding its application boundaries.
Thus, although V4 lacks Engram, its concepts, explorations, and subsequent applications have quietly laid the groundwork for the next generation of models.
What is Engram?
Let’s rewind to January 12, 2026.
On that day, DeepSeek and Peking University released a 33-page paper titled “Conditional Memory via Scalable Lookup.” The first author, Cheng Xin, a PhD student at Peking University, had previously contributed to V3. The last author is Liang Wenfeng.

In short, Engram is a native knowledge lookup module added to Transformers. It allows for quick lookups.
The core observation of the team is that language modeling actually involves two fundamentally different tasks: one requiring deep dynamic computation for combinatorial reasoning, and the other retrieving static knowledge.
The previous issue was that Transformers mixed these two tasks. When the model recognizes an entity, it consumes several layers of attention and feedforward networks to piece together features.
For instance, to recognize “Diana, Princess of Wales,” the model must traverse six layers. The earlier layers struggle with intermediate states like “Wales is a region in the UK” and “Princess of Wales is a type of title,” only reaching the conclusion that this refers to Princess Diana at the final layer.
This “expensive runtime computation to reconstruct a static lookup table” could be handled by the deep network for more complex reasoning.
Engram’s approach is straightforward: since classic N-gram models can capture these local dependencies in O(1) time complexity, why not embed this capability directly into Transformers?
For example, when solving a math problem, you shouldn’t need to derive the formula from scratch each time; you can just look it up. Previously, Transformers lacked this lookup table and had to start from axioms for every problem. Engram provides this table to the model.
Specifically, an Engram module is inserted between the 2nd and 15th layers of the Transformer. Each input position triggers a hash lookup, mapping the current token and several preceding tokens into a massive embedding table to retrieve the corresponding vector directly.
A gating mechanism ensures that irrelevant content is automatically masked when it does not match the current context. For example, while “Zhang” is a common surname, the combination “Zhang Zhongjing” refers to a specific historical figure, which the gating recognizes.
Engram’s role is another sparse axis beyond MoE (Mixture of Experts). MoE sparsifies computation by activating only a portion of experts, while Engram sparsifies storage by only querying a subset of entries. The two complement each other without conflict.
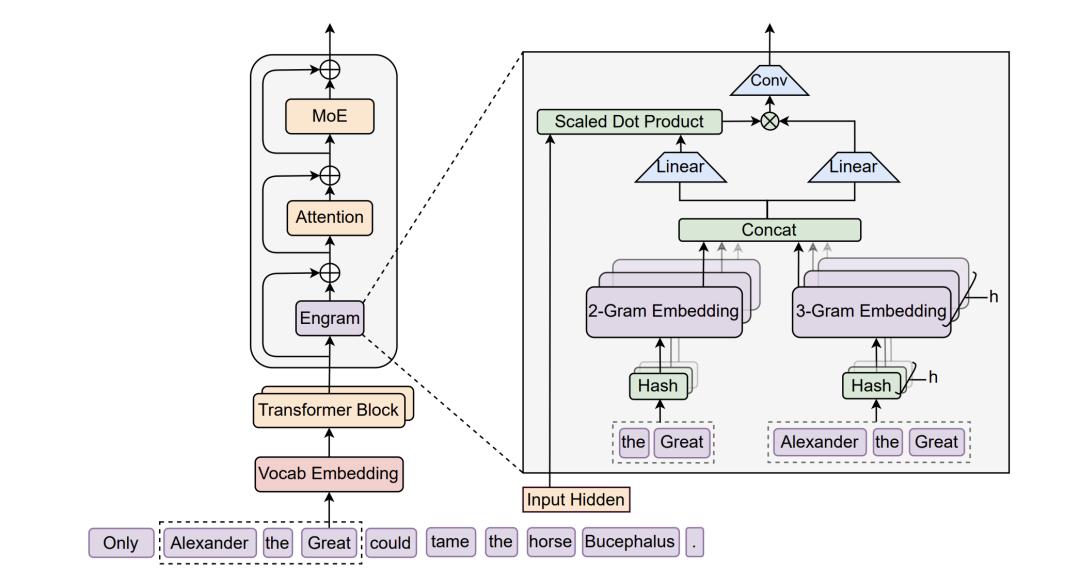
The paper’s core experiment fixed total parameters and per-token activation parameters, allowing MoE experts and Engram memory to compete for budget, resulting in a U-shaped curve.
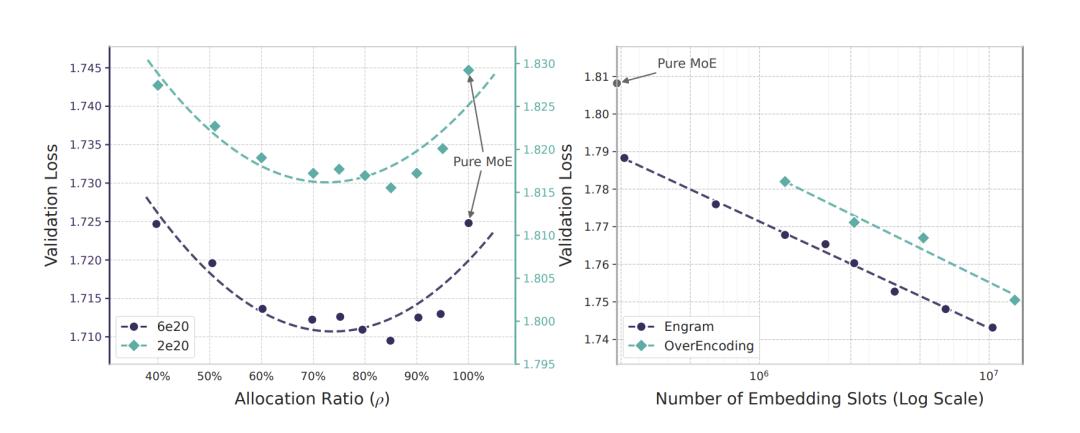
Pure MoE is not the optimal solution. Allocating about 20%-25% of sparse parameters to Engram led to the lowest model loss.
Guided by this curve, the team expanded Engram to 27B, with activation parameters at 3.8B, training on 262B tokens, strictly aligning with the MoE-27B baseline.
The results for knowledge-intensive tasks met expectations (MMLU +3.4, CMMLU +4.0), but improvements in general reasoning and code mathematics exceeded expectations (BBH +5.0, ARC-Challenge +3.7, HumanEval +3.0, MATH +2.4), with even more dramatic results in long-context scenarios, where Multi-Query NIAH jumped from 84.2% to 97.0%.
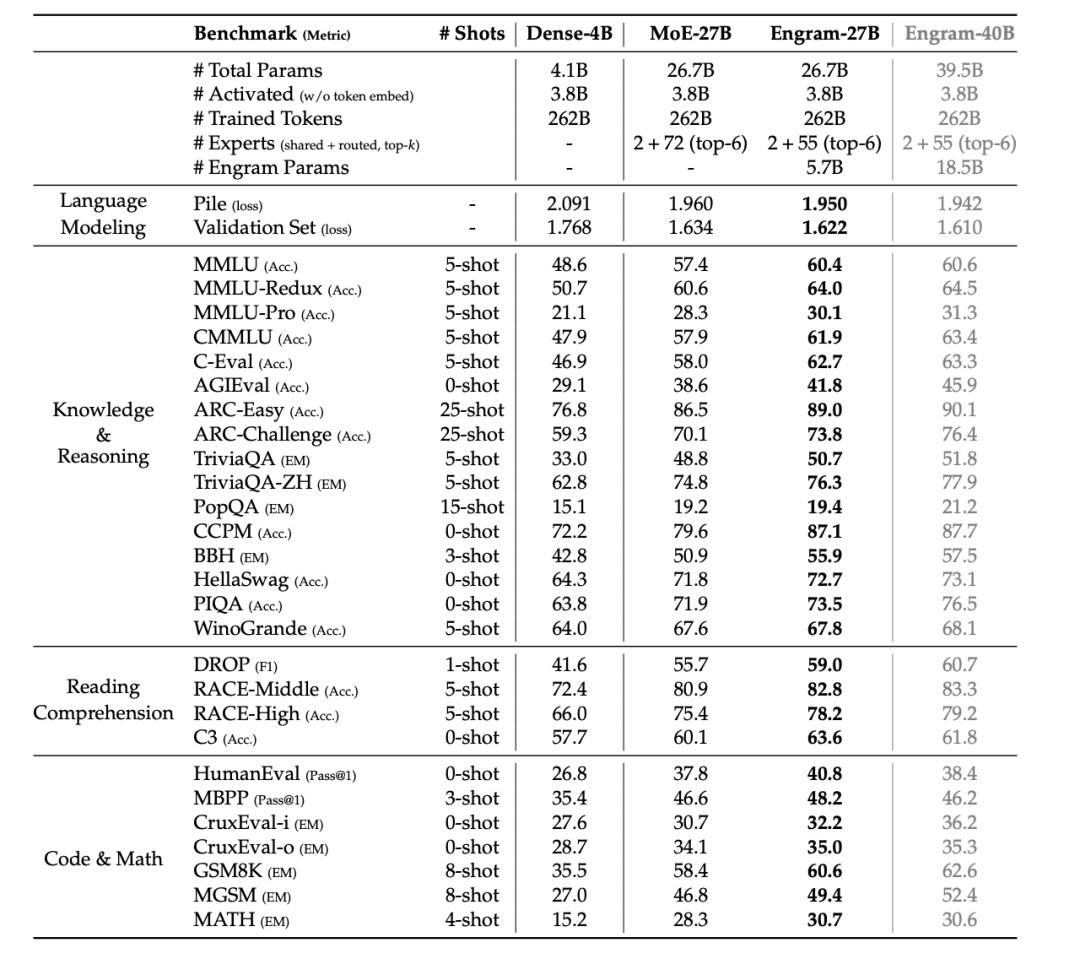
So, why can the memory module enhance reasoning?
LogitLens and CKA provide the answer: the representations at layer 5 of Engram-27B are most similar to those at layer 12 of the MoE baseline.
Engram liberates the model’s early layers from the labor of “reconstructing static knowledge,” allowing this part of the network depth to be repurposed for more complex reasoning. Engram does not merely add a memory component; it also effectively deepens the network.
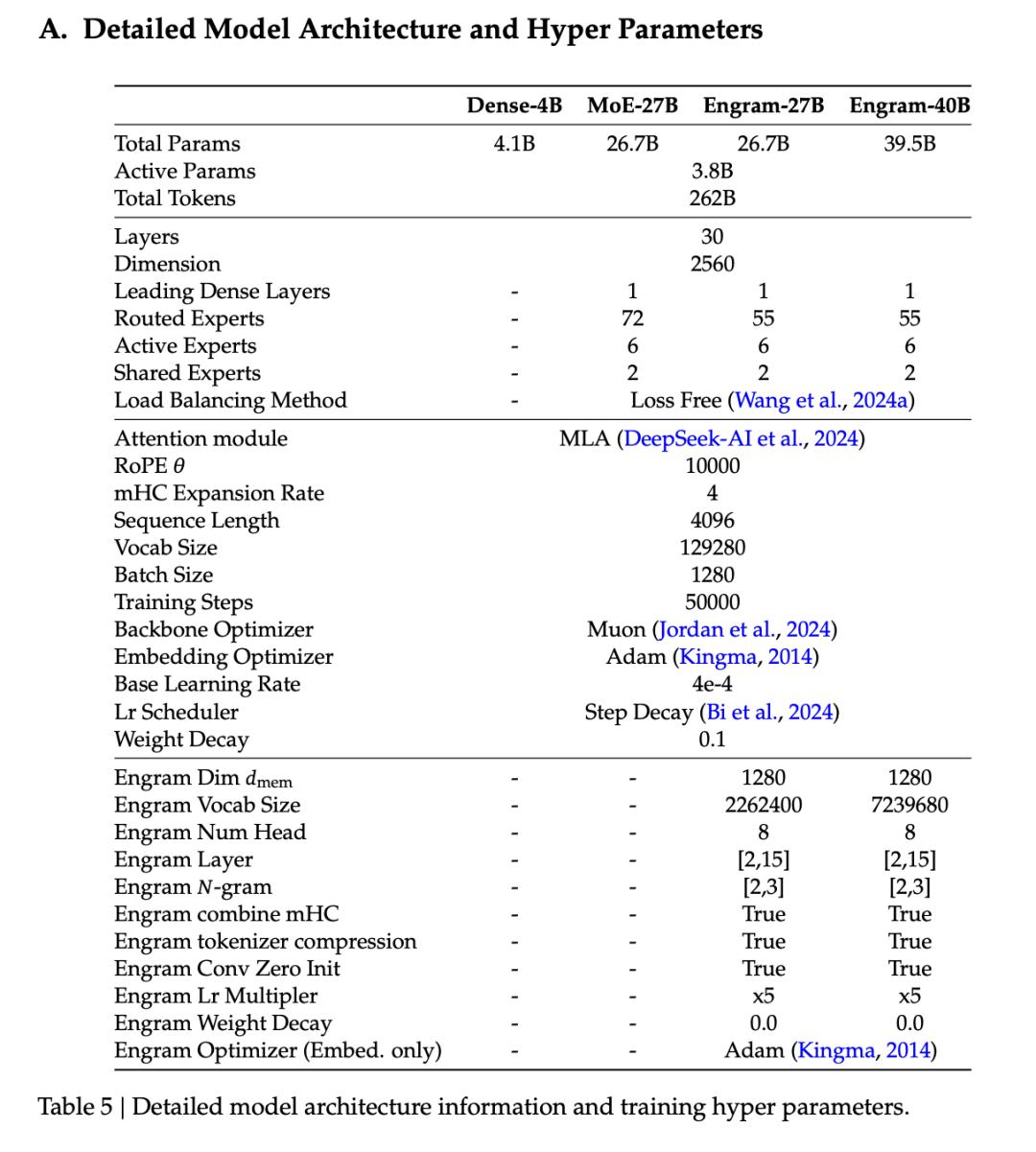
From an engineering perspective, the paper offloads a 100 billion parameter Engram table to host DRAM, running inference on H800, with an 8B-Dense throughput loss of only 2.8%.
This is due to Engram’s deterministic indexing, which solely depends on the input token sequence, allowing for pre-computation and overlapping CPU asynchronous prefetch with GPU computation.
It can be said that this module is inherently independent of HBM, but unfortunately, with V4’s arrival, Engram did not.
Not in V4, but elsewhere
While the inventors left it untouched, others have made strides. In the past three months, at least three notable works have emerged.
Integrating Engram into CXL Memory Pool
On March 10, Peking University, Alibaba Cloud, Shandong Yinxin, Renmin University, and Hong Kong University jointly published a systems paper titled “Pooling Engram Conditional Memory in Large Language Models using CXL.”

They did not alter Engram itself but addressed a more engineering question: if Engram becomes the next standard, where should the memory be placed?
The answer is CXL memory pooling. GPU HBM holds computation weights, local DRAM serves as a secondary cache, and the CXL pool acts as a tertiary cache. Eight servers share a 4TB memory pool, with the XConn XC50256 switch chip managing topology and 512GB/s bandwidth.
This entire setup is integrated into SGLang, achieving prefetch-compute overlap, resulting in an end-to-end throughput loss of less than 5%. The Engram paper’s understated claim of “offloading a 100 billion embedding table to DRAM” has been realized through real tests at scales of 27B and 40B.
The conclusion is clear: Engram’s deterministic addressing and prefetchable load are almost tailor-made for CXL.
An Intuitive Experiment
On January 23, eleven days after the Engram paper was released, a researcher named Tao Lin published a solo paper titled “A Collision-Free Hot-Tier Extension for Engram-Style Conditional Memory.”

He aimed to validate an apparently obvious optimization: if Engram uses multi-head hash tables that might have collisions, would eliminating these collisions with a Minimal Perfect Hash Function improve the model?
He designed Engram-Nine, dividing memory into a collision-free “hot tier” and retaining multi-head hashing in a “cold tier.”
The results were counterintuitive. Under strict iso-parameter control, the collision-free design did not consistently improve validation loss.
Route-stratified evaluation also revealed that the hot path (high-frequency) loss was lower in the early training stages, but in later stages, the cold path outperformed the hot path.
An optimization direction that seemed obvious was disproven by an experimental approach.
Pushing Engram to Visual (AutoArk/Tiny Engram)
A GitHub team called AutoArk developed Tiny Engram.

After fully replicating text Engram based on Qwen-3, they did something not covered in the paper: they adapted Engram for Stable Diffusion.
Visual patches were encoded in layers, capturing textures at the lower level, components at the mid-level, and styles at the higher level, then the entire set was input into a hash table.
Compared to LoRA, Engram achieved similar results with only 15% to 30% of the additional parameters. When continuously injecting multiple new concepts, LoRA showed significant concept degradation, whereas Engram did not.
Originally designed for text, AutoArk effectively opened the door for Engram, allowing it to be applied to any modality that can be discretized and hashed.
In the past three months, while the inventors remained silent, followers have each taken a step forward.
One team addressed multi-machine memory hierarchy, an independent researcher disproved an apparently obvious optimization, and an open-source team pushed it into the visual domain.
Meanwhile, the deepseek-ai/Engram repository has not seen any updates since January 14.
One more thing
The abstract of the Engram paper concludes with a statement:
We believe that conditional memory will be an indispensable modeling primitive for the next generation of sparse models.
It seems that this next generation will be V5; could it possibly be V4.1?
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.